We spend a lot of time working on things that nobody else knows exists.
A seemingly simple act of serving up a photostream with infinite scroll may require global infrastructure, aggressive caching and data being mirrored at the edges of a CDN.
I’m sure there’s some kind of inverse correlation between the delight of a user experience and the challenge of the implementation in software at scale.
This is because in order for the tip of the iceberg to be visible and beautiful, it has to be supported by the 90% of it that exists underwater. The part that others aren’t able to see.
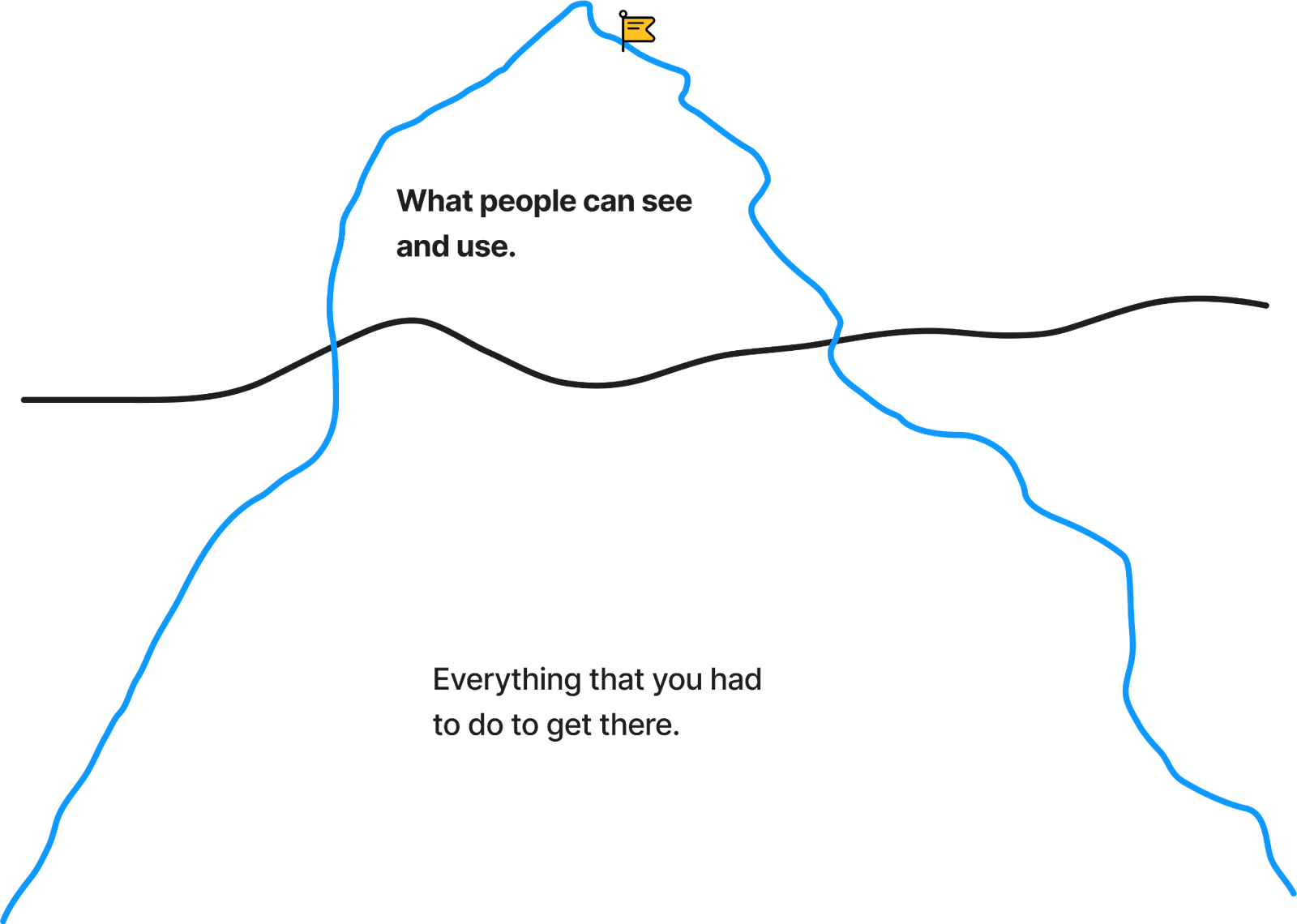
The bigger the scale, the bigger the iceberg.
The better the design, the simpler it appears to everyone else.
Great design fools the world into thinking that the underwater part of the iceberg doesn’t exist. But it does. And it’s hard.
You know the feeling: your design looks so incredibly simple, but the work to bring it to life is immense. And what’s worse is that others don’t understand why your estimates are so large, if you can even come up with reasonable estimates at all.
So it’s no surprise that teams find this challenging to navigate.
How can you get your project off the ground when you need to spend 90% of your time underwater building all of the supporting infrastructure? And how can you prevent the team from getting stuck or producing no visible work for a long period of time?
Well, you’ve gotta understand how to build that iceberg. But this requires a different way of framing your priorities. Teams that struggle to ship big features are often lacking the right strategy to construct their iceberg, rather than lacking the right skills.
When you have a complex project, you’ve got to change the way that you look at it.
A mindset shift: reducing uncertainty
When you’re staring a huge, challenging project in the face, don’t align your team around just getting it done. Instead, align your team around continually reducing uncertainty.
You reduce uncertainty until the software exists. You reduce uncertainty by doing: prototyping, designing, writing code, and shipping. Each of these actions serve to reduce the uncertainty about what is left to build.
When you have zero uncertainty, the feature has shipped. Until then, when you have uncertainty, you aggressively work on reducing it by taking positive action. By doing.
You prioritise the most uncertain parts of your project and focus your efforts on getting answers. Answers fall into two broad categories: that it is possible, as proved by code, or that it’s not possible, but yields another avenue to try. You repeat this process until you’re done, or until you think it’s best to stop.
Focussing on reducing uncertainty builds momentum and trust both inside and outside of the team.
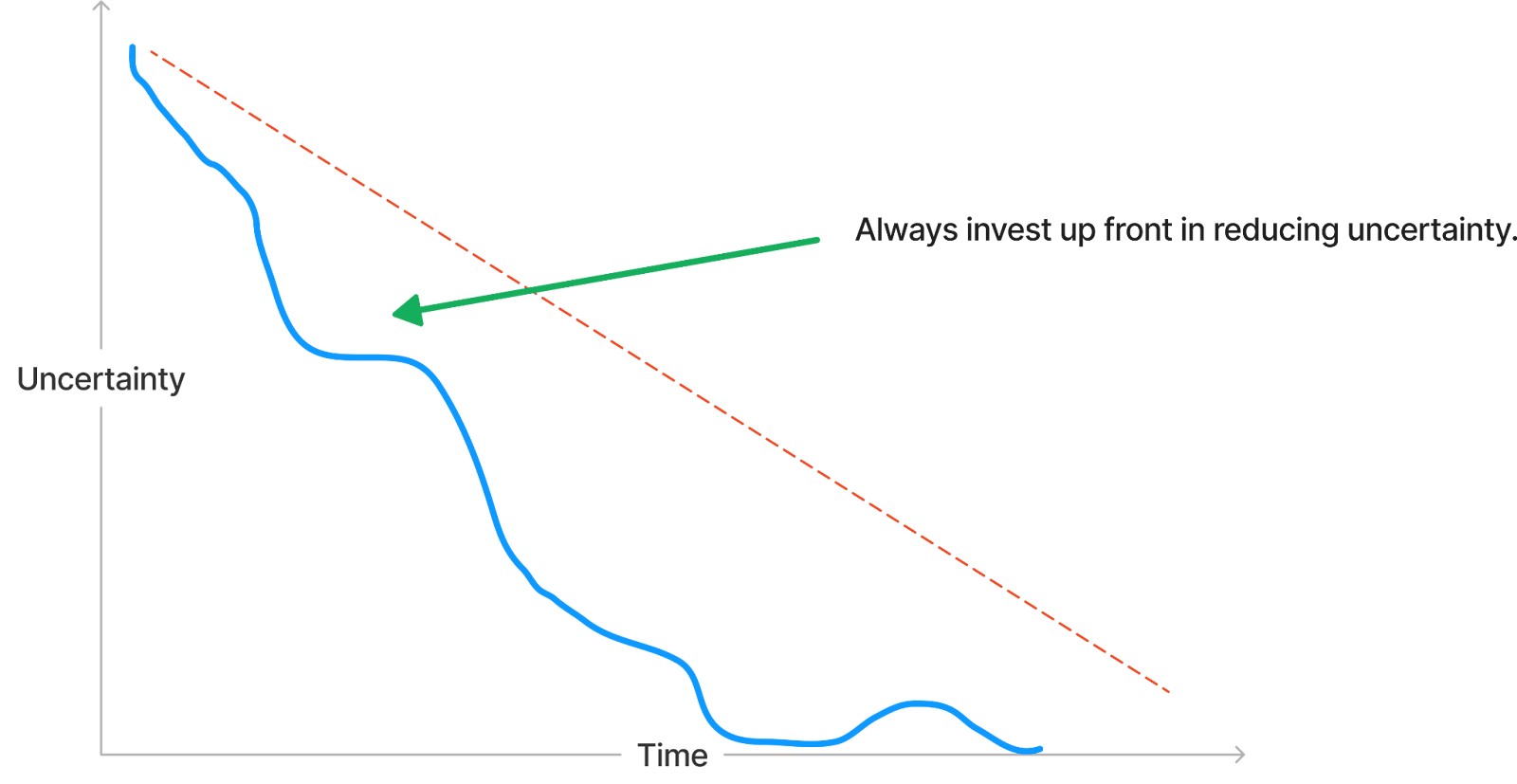
This is because the more uncertainty that you reduce, the more predictability that you gain, and the closer that you get to your goal.
And the more predictability that you have within your team, the more possible that it is to commit to your milestones. Stripping away uncertainty backs the contracts that you have with each other and with the rest of the company.
It says “we’ve got this.”
The worst project crunch happens when uncertainty hasn’t been stripped away up front. If you leave the most uncertain parts until last, you’ll be dealing with them right before the deadline, and the most uncertain parts always have the biggest probability of blowing up in scope and complexity.
Yep, we’ve all been there.
But how do you reduce uncertainty? Let’s look at some examples that you can use as you piece together your own icebergs.
The early stages: prototyping
Your best tool for removing uncertainty at the start of a project is prototyping. And that isn’t just something that designers do. It covers all parts of the stack.
Getting your metrics defined
At the beginning of every project, everything is uncertain. And I’m not just talking about the way in which it needs to be built: I’m talking about whether something even needs to be built at all. So many projects fail because they don’t come up with success metrics that show how that particular project is going to move the needle and be valuable to the company.
If your project doesn’t have success metrics, you probably shouldn’t even start it until it does.
So define them:
- What is this new piece of engineering meant to achieve?
- Is it meant to drive up daily active users by offering a compelling reason for users to log back in?
- Is it meant to increase the average session time by providing more content?
- Can you be specific, with numbers and percentages? With revenue?
I’ve written before about leading and lagging indicators. Defining them up front is one of the most impactful things you can do to reduce uncertainty down the line. You can’t set sail unless you know where you’re going.
Don’t wait to iterate on UX
If you wait until you build something before you start testing it with others, then you’re carrying a huge weight of uncertainty. We all have access to tools that allow us to prototype our UX ideas without writing a single line of code.
Figma prototypes, for example, can look just as real as the final product, but can be built in one hundredth of the time. The more time that something takes to assemble, the more expensive and challenging that it is to throw away. So if you need to rework again and again, do it up front.
Getting your prototypes in front of users—even if they are just internal—can result in significant iterations of the UX before a single line of code is written, driving down uncertainty immediately at the beginning of the project. You might have hundreds of fresh pairs of eyes in your company: use them. They might save you months of work.
Prototyping architecture
Often folks think that prototyping is something that only applies to the user-facing parts of the application, but that is absolutely not true. You want to make sure that the way that you’re storing and accessing your data is right: remember that your job is to reduce uncertainty.
Even if you’re sure about your database schema, don’t let its first real test be with actual users.
Do some back of the envelope calculations:
- Think about the scale that you need to hit now and in the future.
- Create those tables and load them up by generating dummy data, and see how those joins hold out when there are millions or billions of records.
- Make certain that any obvious future additions to your data models have clear paths to follow and that you aren’t painting yourself into a corner.
And if you’ve prototyped your storage, you’re well on the way to defining contracts.
Build: contracts and meeting in the middle
So, you’ve finished your prototyping and you’re feeling good. It’s time to build, and that involves willing that 90% of the iceberg into existence.
However, it shouldn’t be a long march until it’s done. There are still strategies that you should use to keep reducing uncertainty along the way. That typically involves establishing clear interfaces and contracts.
Make contracts if you can’t move in lockstep
Big icebergs need big work. And sometimes, no matter how you cut it, it’s too hard to get everyone across the stack building concurrently in perfect unison. In order to keep things moving use contracts to bridge the gaps.
But what do I mean by contracts? Well, it’s simple really: just make it really clear what is expected from various parts of the system up front, so you can build against those specifications.
A canonical example is defining what the API responses and payloads are going to look like before you actually build them. It reduces the uncertainty at the boundary between the API and the frontend, and it breaks the dependency between engineers, allowing them to focus on building their component pieces against the pre-agreed contract, rather than waiting for each other to be ready.
Contracts go beyond this though. They can be contracts about the desired performance and trade-offs of the system. For example, which interactions need to be synchronous and which can be asynchronous? What’s an acceptable P99 for a certain action? What sort of size of response are we expecting in each scenario?
Defining these contracts up front not only decreases uncertainty, but it also opens up possibilities for building better user experiences by understanding how the machinery is working underneath and working with it, rather than against it.
Static data can replace whole backends
If your team is building a particularly complex backend system that may take some time, then you might even want to build an API with static data so that frontend engineers can work against something that feels real, even if it isn’t. You could create database tables containing dummy data with the real API in front of them, or you could even just serve up some static JSON files.
Not only does this reduce uncertainty by getting to something that feels like a real working system more quickly, it allows all of the inevitable snags and omissions to come to the surface much, much quicker. That missing sort option you forgot about? That additional column that would be useful to store? Yep, you’ve experienced that snag before the system is built.
If you’re a backend engineer on a complex feature, never let the first time that your API or data is used be when you’ve finished building it. Let static data take the initial contact with the rest of the system so you can build the real thing with far less uncertainty.
High fidelity mock-ups leave nothing to guesswork
Moving up the stack a little, there’s nothing worse than deriving a UI build from intuition and then realising that it just doesn’t feel right when you use it. Whenever you can, use high fidelity prototypes that look and feel like the real thing in order to feel the product—and whenever possible, run it by users—before it is built.
In addition to uncovering all of the snags that exist in your workflow designs, your high fidelity mockups make frontend work so much easier. It acts as another form of contract, allowing engineers to work from them side-by-side with their code, asynchronously, and there is no doubt what pixel perfect looks like: it’s right there in the mockup.
This frees up designers to focus on future iterations, laying out the path for the team to follow.
Launch: the tip of the iceberg
Once you’re getting ready to ship to users, you still need to focus on reducing uncertainty. And there’s a lot of it when it comes to launching and scaling a product.
Feature flags are your friend
If you’re not already deploying continually behind feature flags, you should be. Feature flags allow you to deploy code into production early but only toggle that functionality on for specified users or cohorts.
As well as allowing you to do A/B testing or to release early to beta groups, feature flags allow you to reduce uncertainty by merging your code into the main branch far, far earlier. This prevents chains of pull requests, stale branches, and most importantly, prevents big bang launches where you need to ship to production and launch a product at the same time.
Feature flags allow you to use your new features for real, even if you’re the only ones that can see them. And then the best part is, when you’re ready to launch, you just turn on the feature toggle for all users and clean up the toggle in the code.
You just lift the curtain and show what was already there. Your marketers can run the go-to-market campaign when they want and with confidence.
Shadow deployments
For many engineers, the difference between development environments and production environments can be vast. It’s like crossing a chasm.
Users, traffic, and increase in data means that any new backend system that you are deploying is going to be under significantly more load in production when compared to development, and the shape of real usage and traffic is always different to any synthetic load testing.
You can greatly reduce uncertainty by using a technique called shadow deployments, which is where you deploy your new backend system into production and route traffic towards it even though it’s not being used. If you can measure both ingress and egress paths, you can observe your new system under real load without the risk of users experiencing any performance problems. They don’t even know that it’s there.
In the past, I’ve been part of projects that had shadow deployments of infrastructure happening at the multi terabyte scale. And if it went wrong, nobody knew. And what’s great is that the longer you have a shadow deployment running collecting real data, the less you have to migrate when it’s time to switch it on for real.
Standing on the shoulders of giants
Big projects are all about reducing uncertainty while you build the 90% of the iceberg that nobody else is going to see. We’ve touched upon a number of strategies that you can use to do so.
However, here’s a closing thought: given that a zero to one project build involves investing significant amounts of time constructing our iceberg underwater, why don’t we spend more time capitalising on it when it’s done?
I’ve noticed that the most productive time for shipping additions and improvements to a feature is in the 6-12 months after it has been initially launched. The code is new, the context and kinetic energy within the team is high, and there is often a rich backlog full of ideas that didn’t quite make the cut for the first version.
Making sure that a team is able to continue iterating on what they’ve shipped allows for low uncertainty improvements that are all visible at the top of the iceberg.
But here’s the catch: some organisations are so desperate to move on to the next feature (see feature factories) that they completely miss this magic window where the team is on fire.
So if you’re a leader, don’t be so quick to move on: your most predictable and impactful work can come in the period right after shipping. The iceberg is there. You can keep building upwards.
Software development can spend a lot of time underwater. But if you think about projects as a process of aggressively reducing uncertainty, then you can maximise the opportunities for the tip of your iceberg to be visible to yourselves and others as you progress. And once it’s built, don’t be so fast to move on.
Know your metrics, prototype and iterate while it is cheap to discard work, create contracts to break apart dependencies within the team, and have code in production under load way, way before launch.
Then, when it’s done, keep building.
Pingback: 10 interesting newsletters for CTOs and engineering leaders